
对doc类型的页面进行解析

一. 背景
在公司的erp系统中,还有很多jsp写的页面没有做前后端分离,一些重要信息没有写入到cookie,也不是通过接口返回,直接嵌入在页面中,例如 token字段。
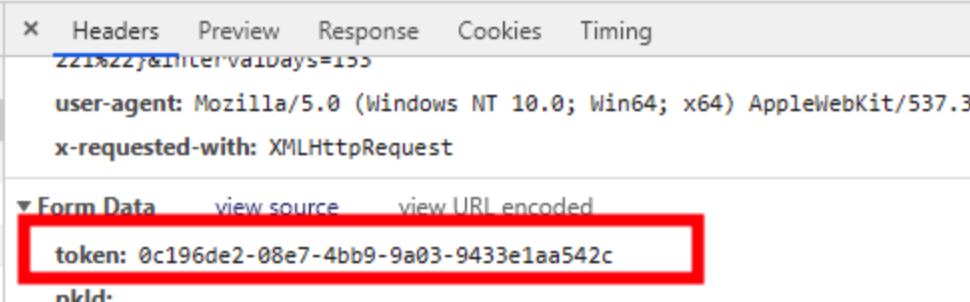
一开始以为可能在cookie里,发现找不到,咨询开发,得知是后台返回的,那什么时候返回 ?返回到哪去了?
逐步排查,发现该字段是在点击新建工单后,通过返回的页面带出来的。

直接返回一个html,是doc类型

二. 使用beautifulsoup进行解析
1. 什么是beautifulsoup
beautifulSoup,一个灵活又方便的网页解析库,处理高效,支持多种解析器。
不同解码器适用不同场景,各有优缺点,如下:
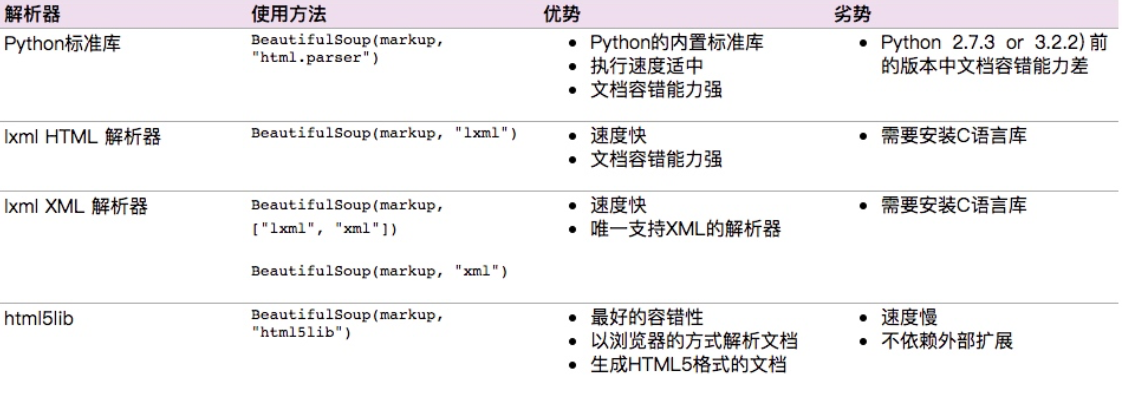
一般使用较多的就是lxml来解析html。
2. 安装beautifulsoup
beautifulsoup需要单独安装(这里安装命是他的缩写: bs4)
1 | pip install bs4 |
3. 使用beautifulsoup
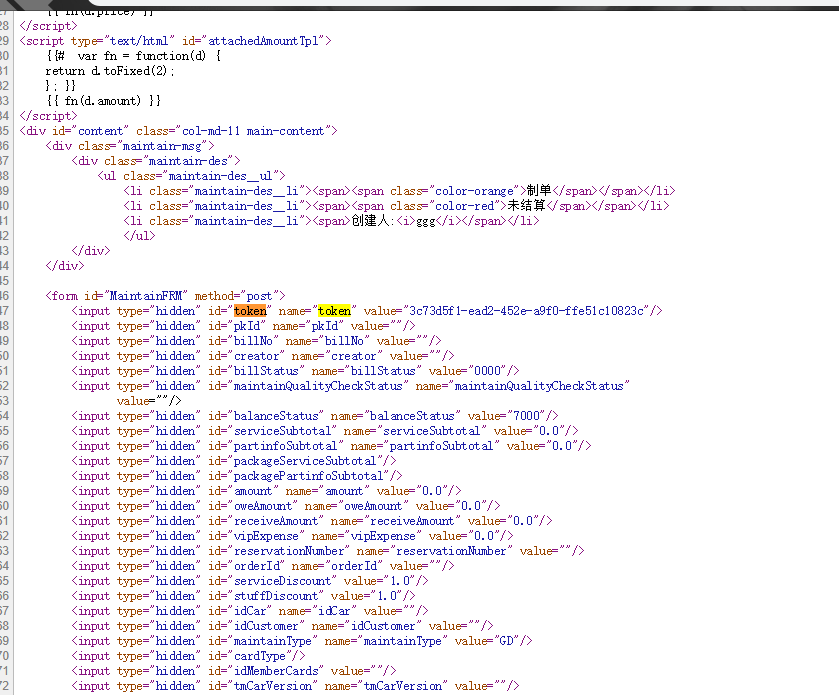
页面源代码如下(部分)
1 | from bs4 import BeautifulSoup # 引入BeautifulSoup |
如图,input的id为token,而我们要取他的一个属性–value,因此。在使用beautifulsoup解析后,就可以访问其中的任何节点,使用方式有点像selenium。
这边用的select,返回的是一个列表,当然,id唯一,固定取第一个,下标传0,这样就取到了这个input,然后获取他的value的值。
三. 拓展
上文示例,只是获取节点的一种方式,还有多种方式可以来实现。
感兴趣可以自行看文档,推荐文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/index.html
四. 使用re模块正则匹配取值
有些老页面,例如业务分类
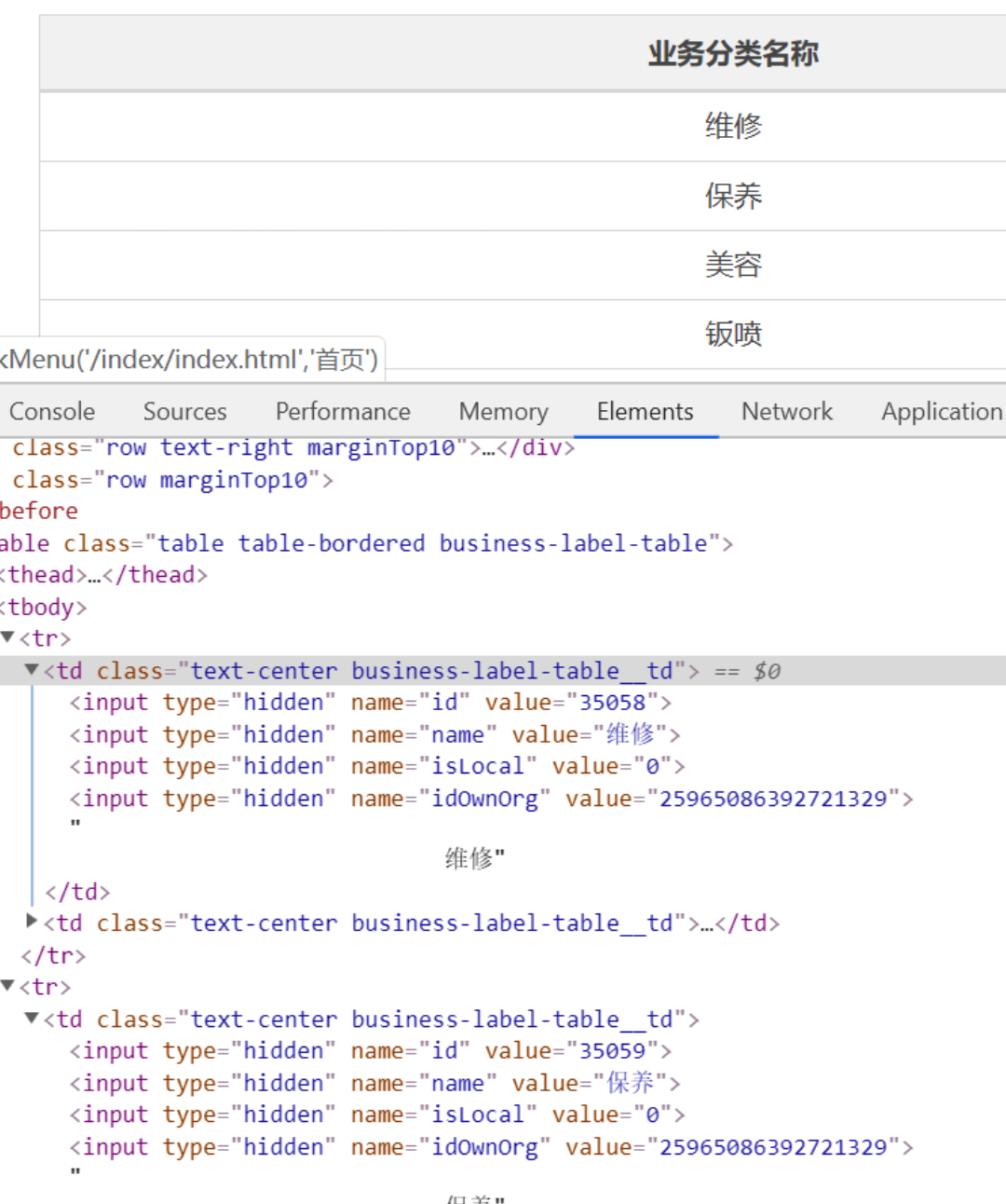
这些不是接口返回,是随着页面直接返回的,但是这种太多了,通过html解析器再去找也挺麻烦的。
那么这些信息是后台直接渲染好的么?从源码中找找。
随便找个分类“维修”查找下

发现,原来这些信息通过script渲染的,幸运的是,我们能直接从源码中获取,而不必通过Ajax动态获取。
OK,到这里,就明了,内容都给你了,直接正则匹配获取吧。
先写表达式
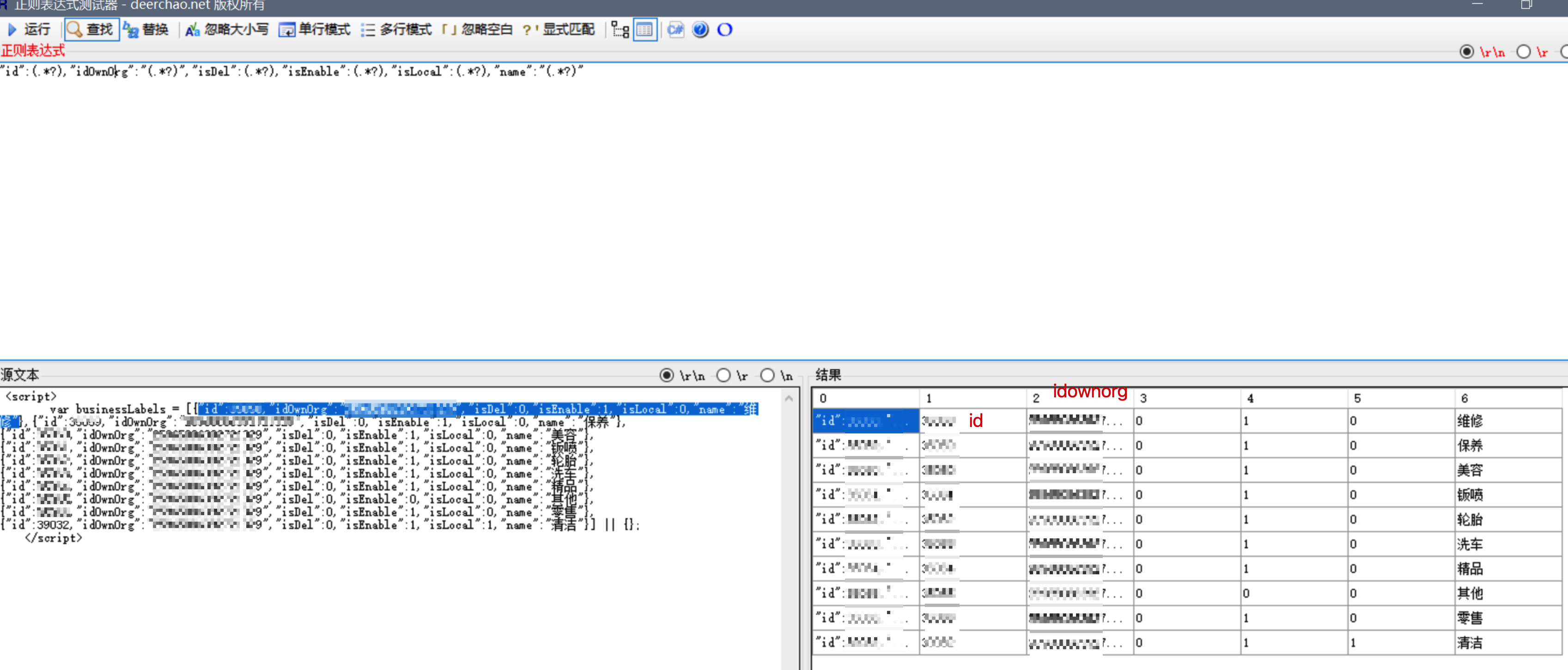
OK,都匹配出来了。
使用re模块进行正则匹配,这里需要匹配多项,使用finall。
1 | # -*- coding: utf-8 -*- |
结果
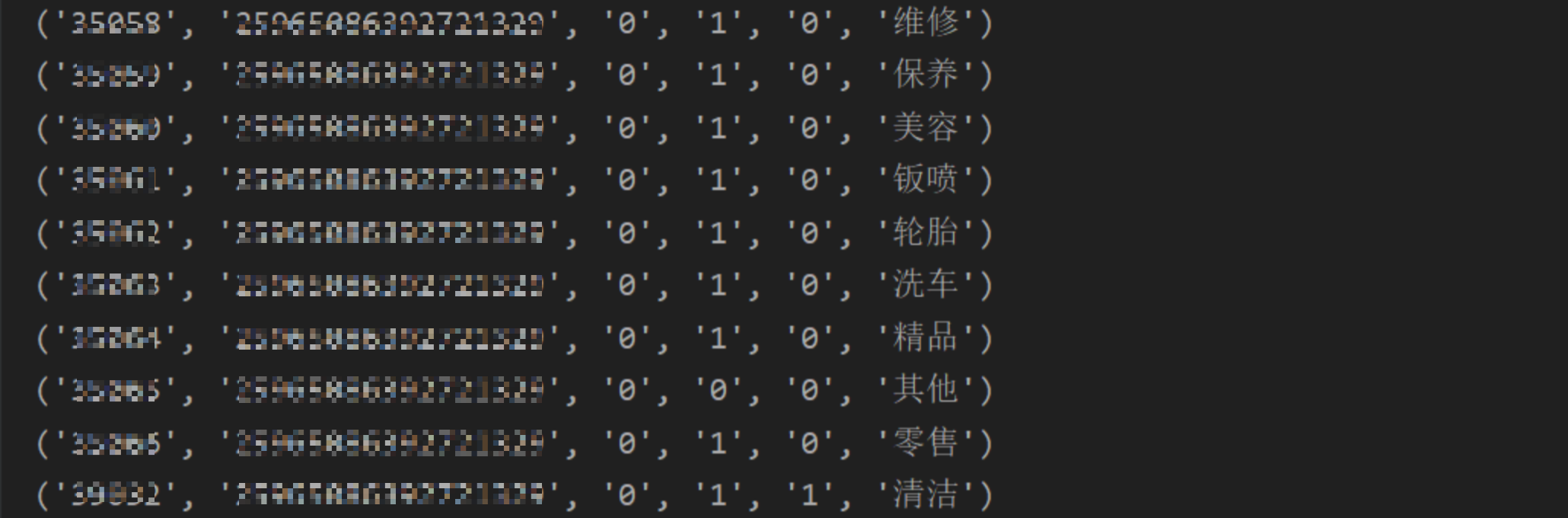
结果取出来之后,再自行加工吧~