jmeter基础元件(四)-- 前/后置处理器

首先,理解下前置后置的动作,假如说sample是正式的动作,那么前置和后置就分别是正式的操作之前和操作之后的一些步骤。
一. Pre Processors (前置处理器)
1.User Parameters
从字面上看就是定义变量的。看看长啥样。
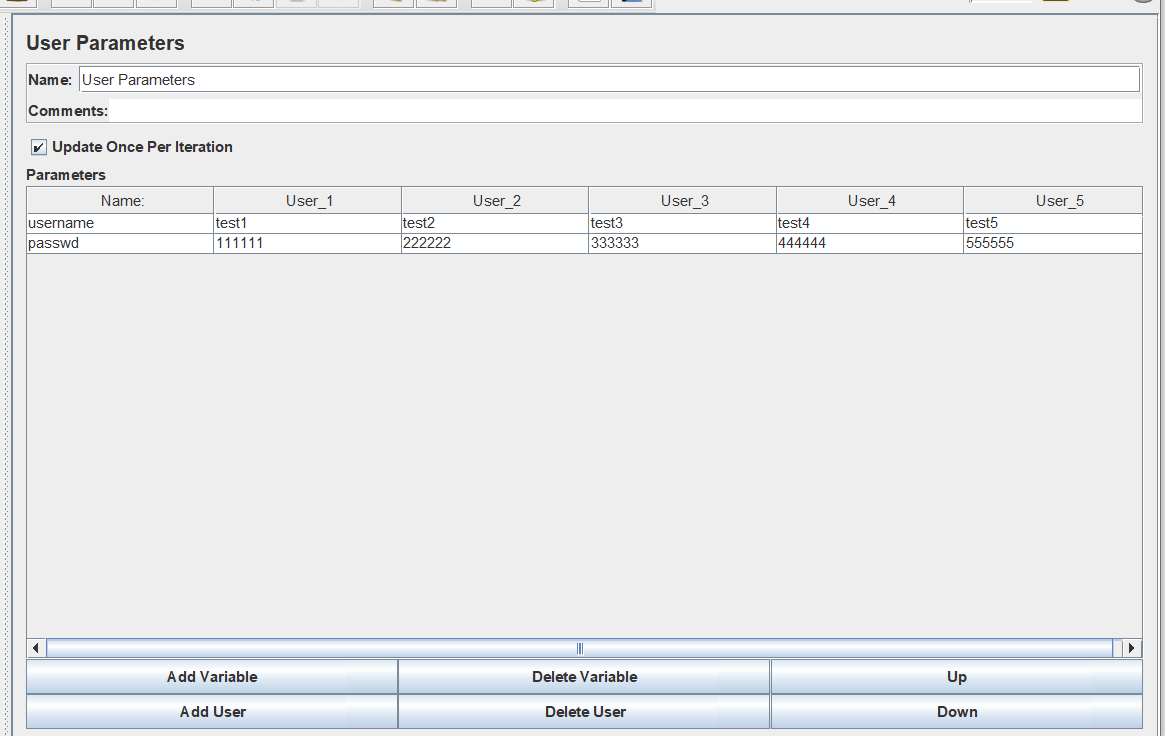
可以看到有variable和user两个,添加两个varaible,一个叫username,一个是passwd。
添加多个user,分别赋值。
然后添加一个http请求,命名下name,其他不用设置。
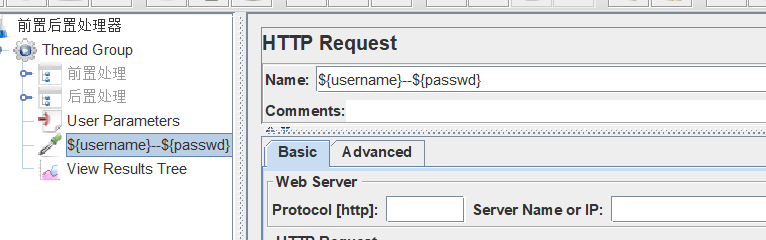
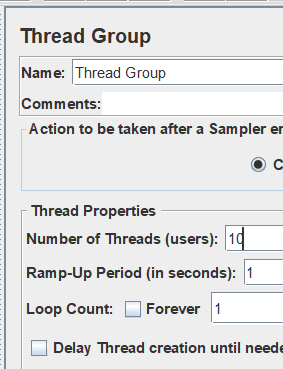
线程组设置如下,结果为:
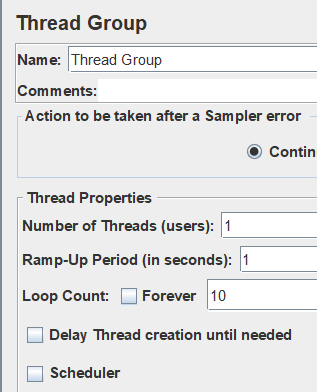
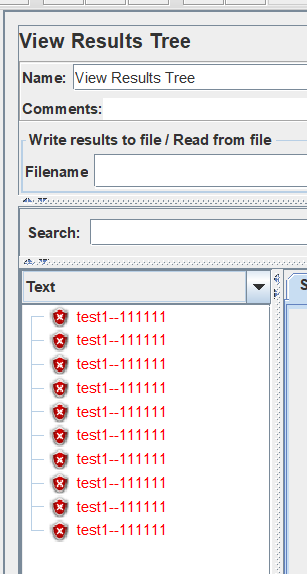
线程组设置如下,结果为:
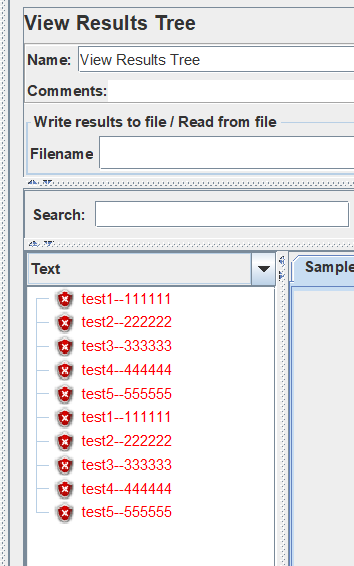
OK,可以得出结论了,定义变量的时候为什么叫add ueser,原来是跟线程数挂钩的,一个线程可以理解为一个用户。假如一个变量有多个值,每个线程按照线程顺寻去循环定义的变量。
这样的效果有点类似于CSV Date Set Config ,但是如果参数的取值范文很大,建议还是使用CSV Date Set Config更方便点。
而User Parameters和User Defined Variables也有些类似,只不过从上面的结果可以看出,User Parameters适合一个变量有多个值的时候,而User Defined Variables则是只有一个值,一些不会再改变的参数可以使用User Defined Variables定义。
2.HTML Link Parser
HTML链接解析器。主要用于解析前一个请求的返回内容,然后根据规则去解析出HTML链接然后一一访问。
以百度搜索为例,先写一个访问百度搜索的html请求。
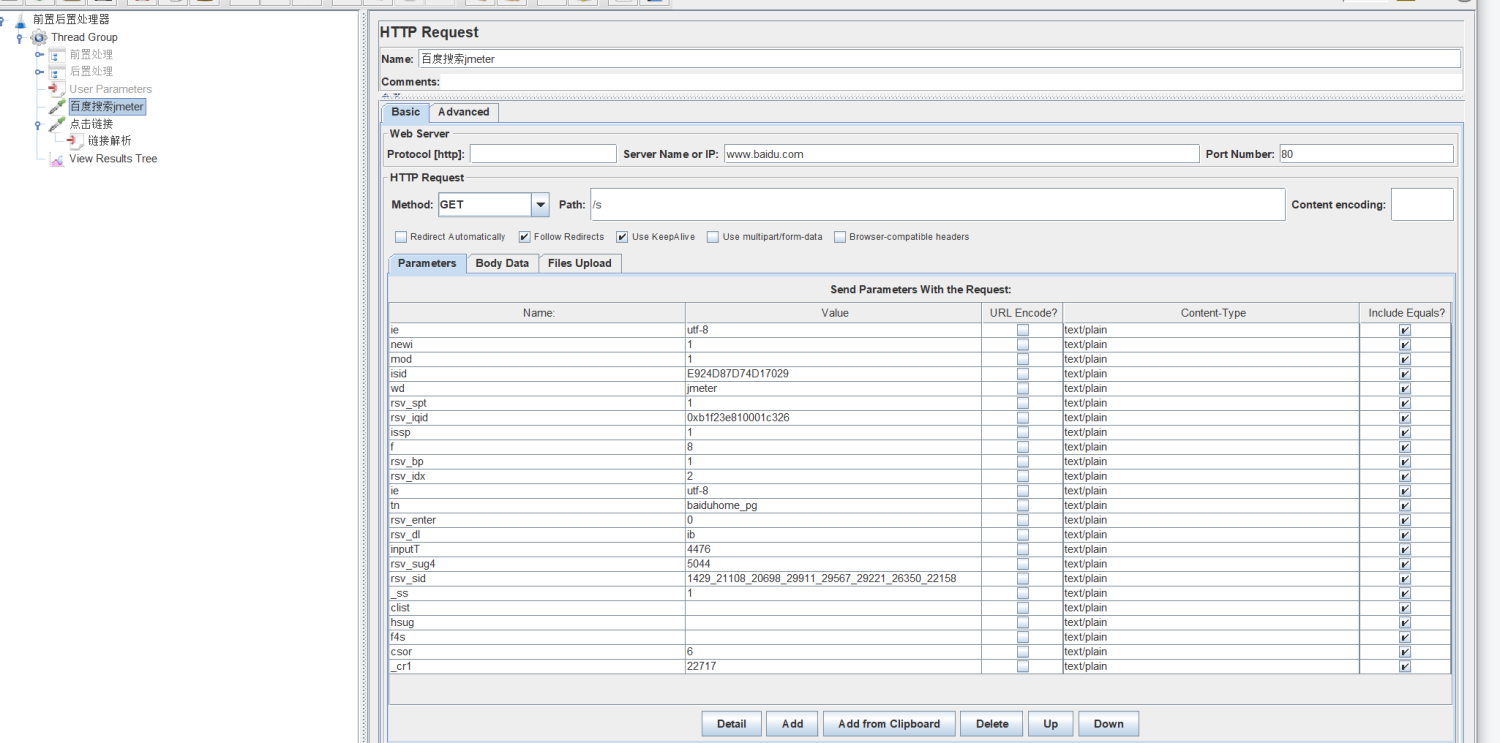
在下面在建一个请求,并在请求下面添加HTML Link Parser,然后再请求的server anem or ip和path 处填写匹配规则,这边举例我就简单点写 .*了。
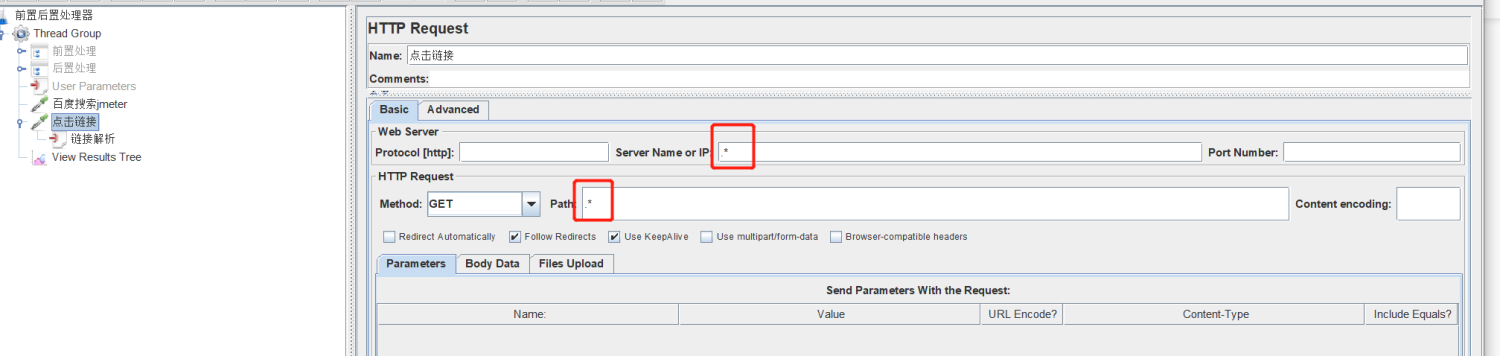
运行一个。
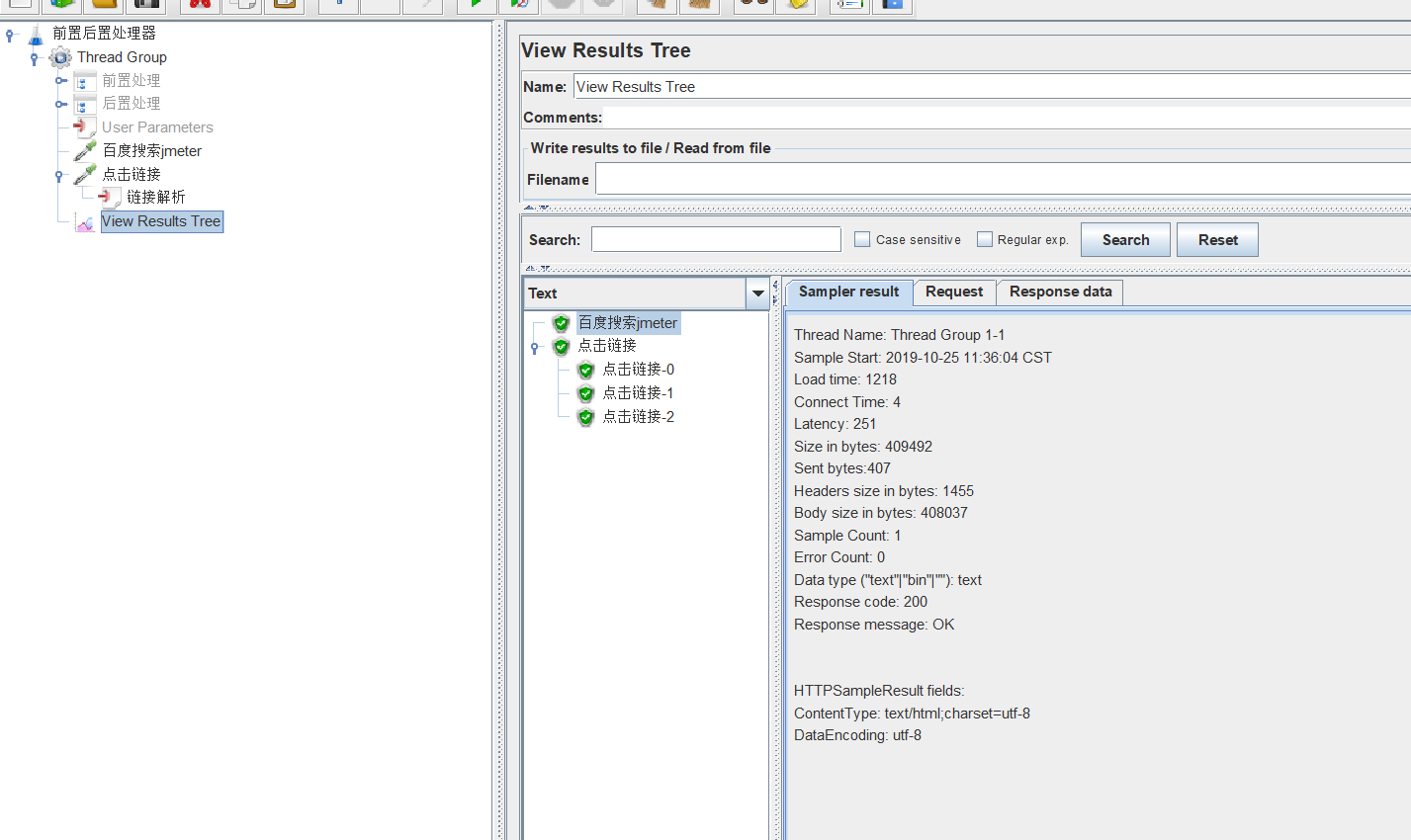
可以看到,搜索完jmeter之后,解析出三个链接地址,然后去访问了这三个链接。
(这里写的有问题,搜索结果没完全返回,先不管了,主要理解这个作用。)
3.HTTP URL Re-writing Modifier
顾名思义,这是修改重定向地址的。类似于HTML Link Parser,但专用于使用url重写来存储sessionId而非cookie的http request,在线程组级别添加此修改器则应用于所有sample,若为单个sample添加则只适用该sample
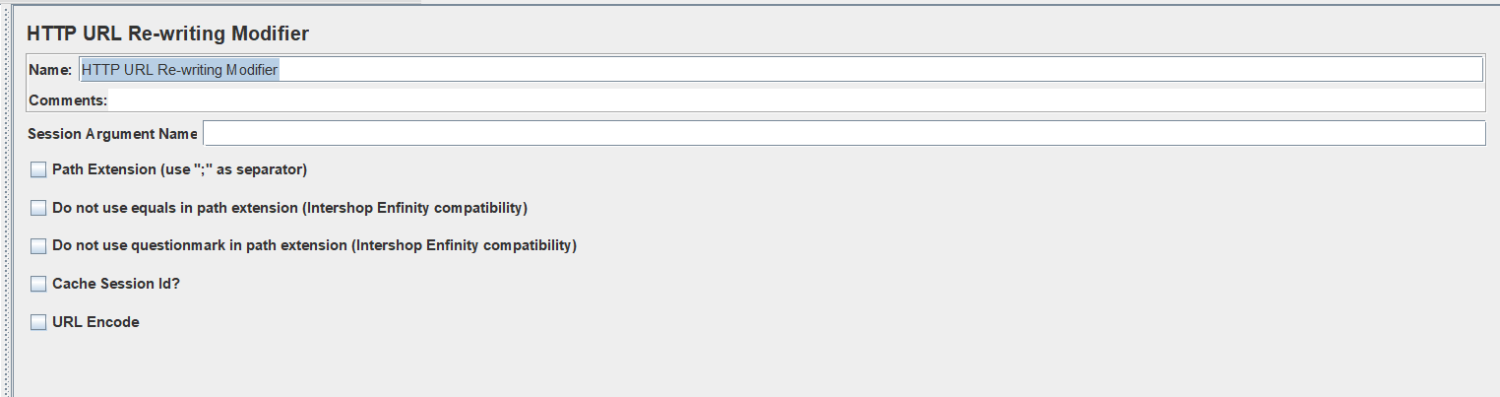
Session Argument Name:会话参数名称,用于搜索sessionId,其他sample也可通过此参数来 调用其获取的sessionId;
Path Extension:路径扩展,如url添加了分号作为分割,则勾选此项;
Do not use equals in path extension:用于url不用等号来分割key和value的类型;
Do not use questionmark in path extension:用于不带?的类型;
Cache Session Id?:勾选此项则会存储在其挂载的sample上获取到的sessionId供后边的其他sample使用;
URL Encode:是否使用url编码;
4.JDBC PreProcessor
数据库预处理器,这个主要作用是在当前的请求开始前去操作数据库做一些操作。
Variable Name of Pool declared in JDBC Connection Configuration:连接池名称,需与JDBC链接配置中的Variable Name相同(此预处理器需要一个JDBC Connection Configuration,此配置器在配置元件中);
Query Type:数据库查询类型,根据需要自行选择;
Query:数据库语句输入框,根据需要输入,注意结尾不要加”;”;
Parameter values:参数名称,如果Query的语句中有”?”则此处填值,可以使用调用参数方式;
Parameter types:参数类型,与Parameter values对应,设置参数类型,与sql字段类型相同;
Variable names:设定此项可以获取固定列的所有值;
Result variable name:随意设定一个名称,则此名称会被作为一个参数并对应Query出来的内容;可以使用参数调用的方法来获取此设置的名称对应的值;
Query timeout(s):超时时间;
Handle ResultSet:有四个选项,结果保存的方式;
5.RegEx User Parameters
正则表达式,可以将上一个接口的参数提取作为新的自定义变量,一般前一个请求使用了post processor

这个没找到好的案例,没get到他的作用,略过。
6.Sample Timeout
超时器,用来设置sample的超时时间,如果sample的完成时间过长,预处理器会调度计时器任务以中断样本。

milliseconds是毫秒,1秒=1000毫秒。
我这边设置成10000,表示超时时间为10秒。
7.BeanShell PreProcessor
这是一个前置BeanShell处理器,可以在他下面的samples执行前,执行任何代码。比如说获取一个时间戳。beanshell的用法都差不多,位置不同,导致触发的时机略有差异,不多说了。
语法格式等参考BeanShell取样器。
二. Post Processors (后置处理器)
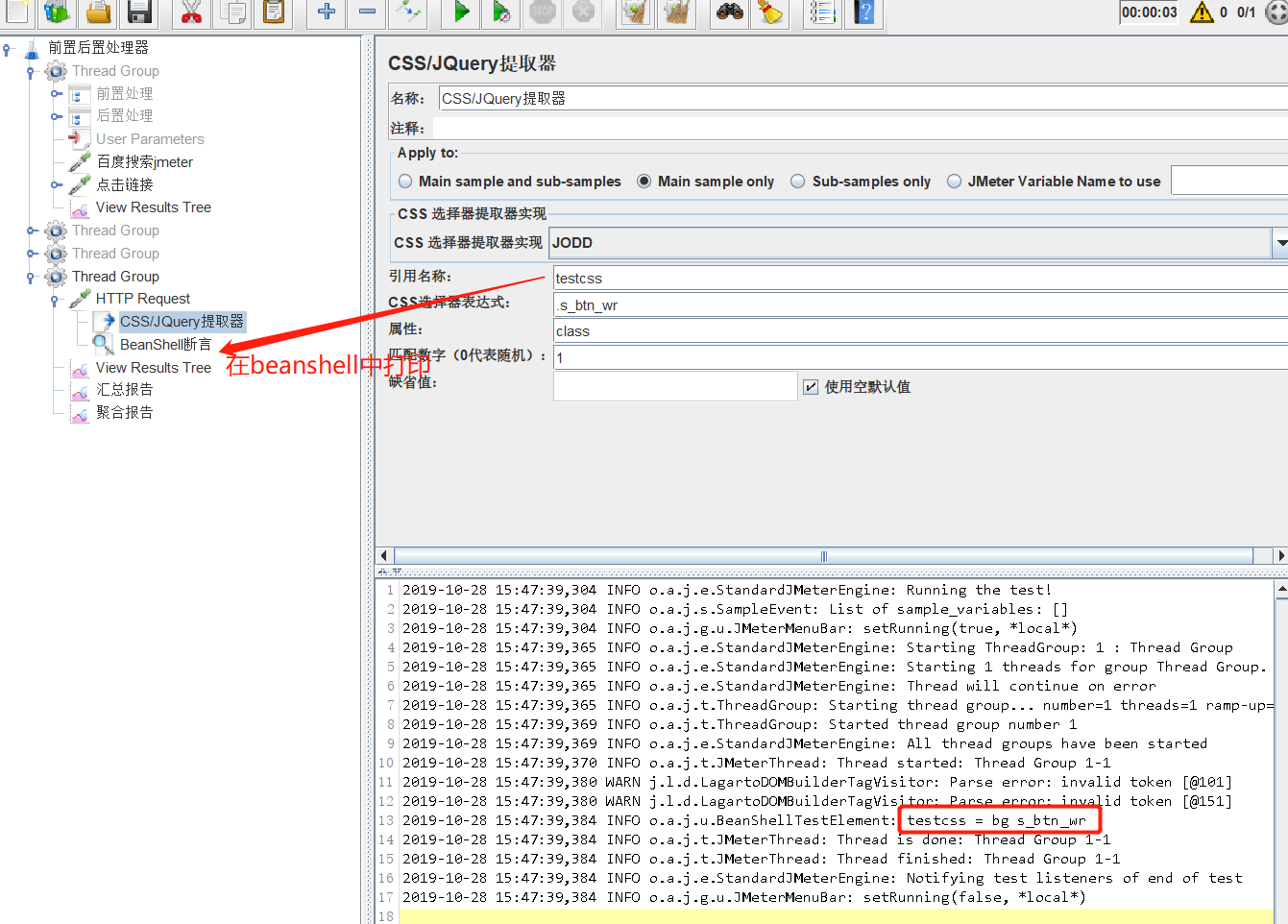
1.CSS Selector Extractor
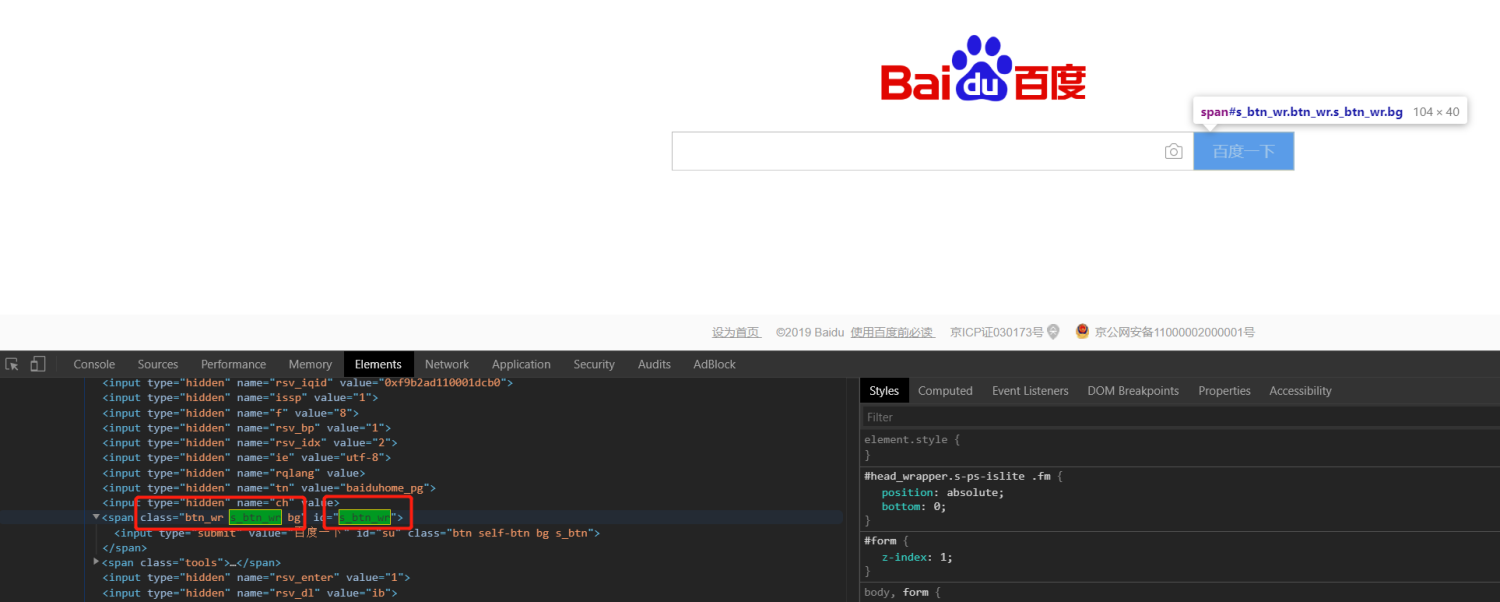
CSS/JQuery提取器,允许使用CSS / JQuery选择器语法从服务器响应中提取值,否则使用正则表达式可能难以编写。从请求采样器中提取所请求的节点,文本或属性值,并将结果存储到给定变量中。CSS无法走向DOM。
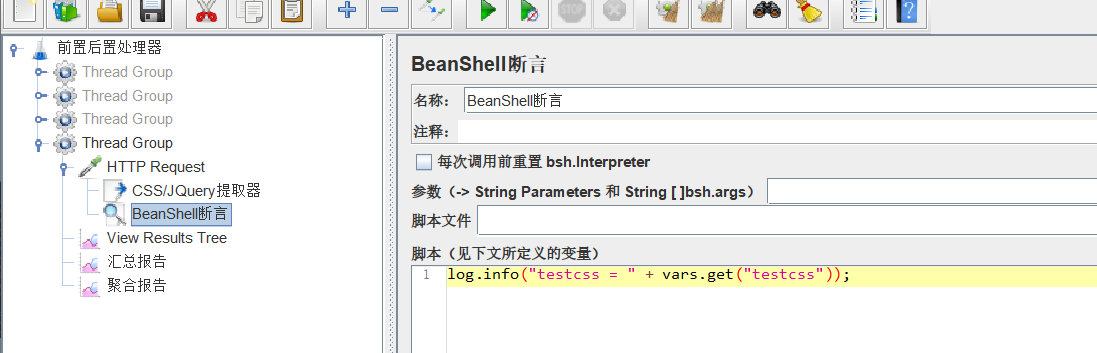
例如,通过以下id定位到这个元素,然后把他的class赋值给变量testcss,最后在beanshell sample中打印该变量。
2.JSON Extractor
JSON提取器
和上面类似,不过json是专门用来提取json的,例如一个访问一个url,这个url是个接口,返回的是一个标准的json格式数据,那么可以使用该提取器进行提取。
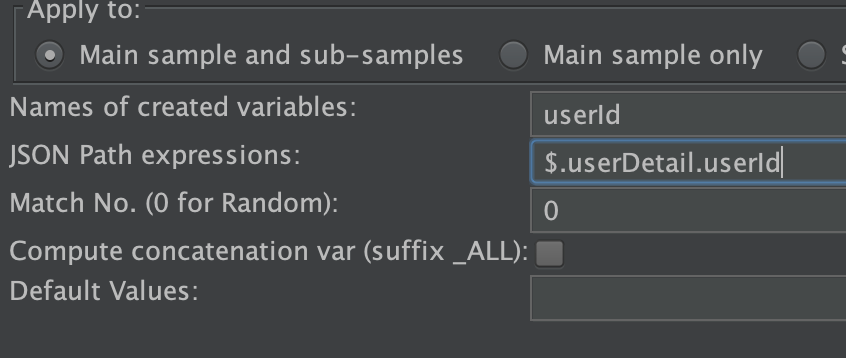
例如需要匹配的内容是,需要提取出userId
1 | { |
写成如下
3.Boundary Extractor
边界提取器,它通过左右边界来提取需要的内容。
它可以匹配任何格式的内容,如文本、json、xpath、html等等
使用也很简单,分别填写要提取内容的左右边界即可,很灵活。
边界提取器可以替代正则表达式提取器和JSON Extractor。
例如”
哈哈哈
“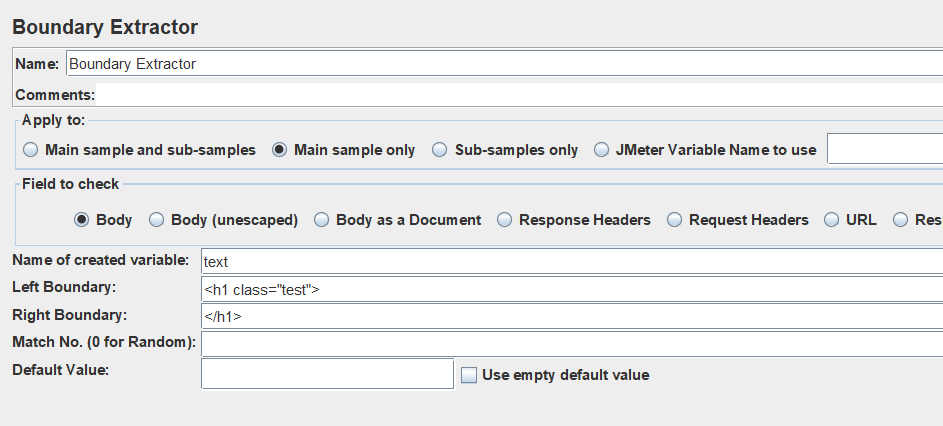
匹配出来的“哈哈哈”就是text。
4.Regular Expression Extractor
正则表达式提取器,这个也是用的比较多的提取器,尤其是对于一些老的页面,很多内容不是通过接口返回的,而是直接把结果渲染在了模板上,模板直接返回html代码,这个时候就需要使用正则表达式提取器,通过正则表达式吧来提取内容。
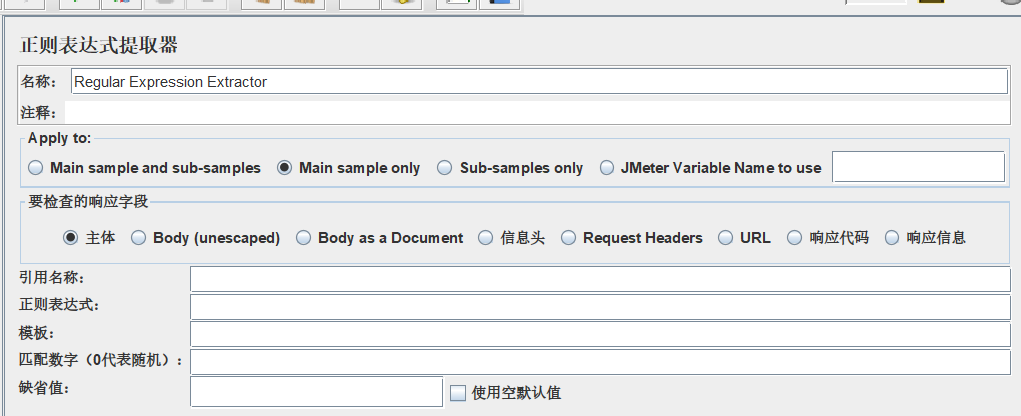
下载一个regex.exe小工具,直接匹配好规则,填写到正则表达式里去就行了。
补充说明相应字段的范围:
主体:response body默认
Body(unescaped):是替换了所有的html转义符的response body
Body as a Document:替换了转义码的response body部分
信息头: response header
Request Headers:request header
URL: 只匹配url链接
相应代码: 匹配响应代码
相应信息:匹配响应信息
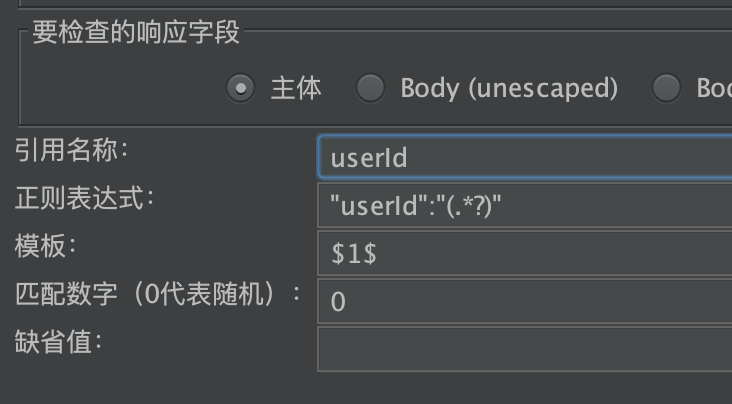
例如从接口返回信息为:
1 | { |
提取userID
5.JDBC PostProcessor
JDBC后置处理器, 和前置的JDBC处理器功能类似,就不多说了。
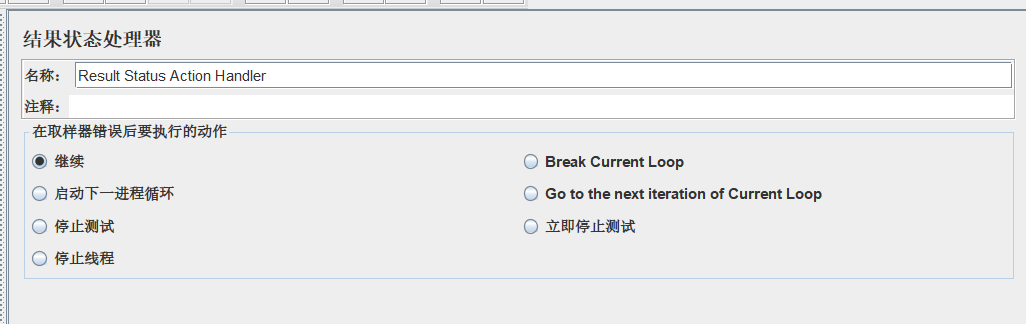
6.Result Status Action Handler
结果状态处理器, 这个也不必多说了把,专门用来控制一个sanple失败后的动作,比如忽略错误继续执行,比如这一进程结束,开始下一进程,比如停止测试计划,停止线程等。
7.XPath Extractor
XPath提取器,XPath可用于浏览XML文档中的元素和属性。当使用正则表达式提取器无法提取响应中的数据时,它可能很有用。例如多个li,要获取他们的text,通过正则处理会比较麻烦,而使用xpath则比较简单。
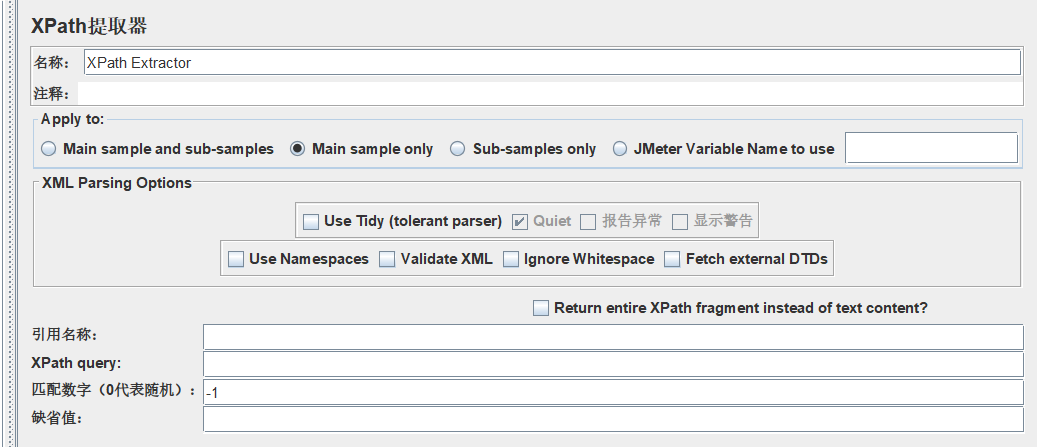
Use Tidy:当需要处理的页面是HTML格式时,必须选中该选项;如果是XML或XHTML格式(例如RSS返回),则取消选中;
Quiet: 表示只显示需要的HTML页面,Report errors表示显示响应报错,Show warnings表示显示警告;
引用名称:匹配后定义成变量
xpath query: 写xpath表达式
匹配数字:0表示随机返回,-1表示所有,其他正数1,2,3则表示对应匹配到的第几1,2,3个
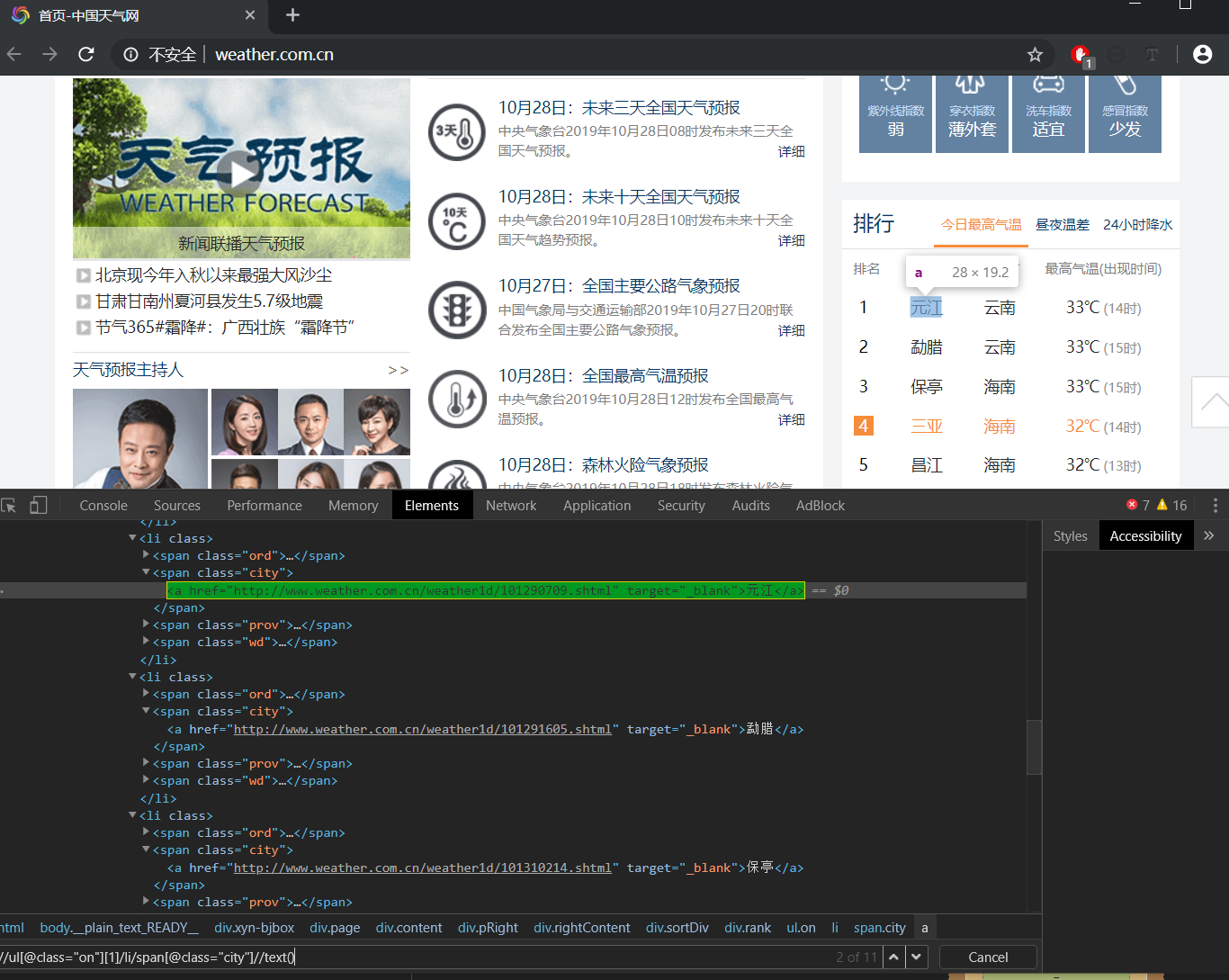
举个例子,获取这个天气网站今日气温最高的10个城市,第一个是标题可以忽略。
xpath没问题,放到jmeter中去。
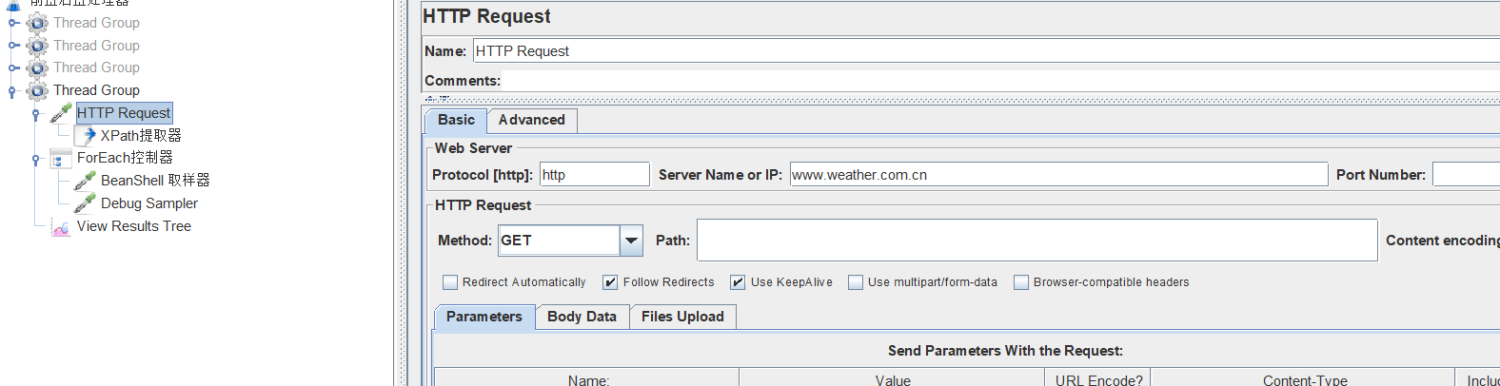
将匹配到的赋值给变量city
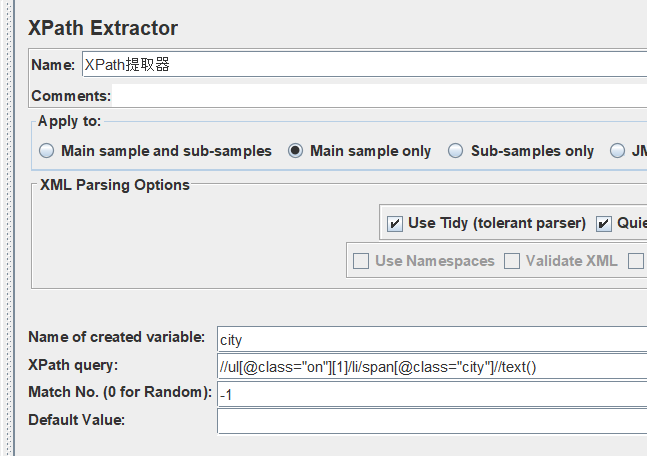
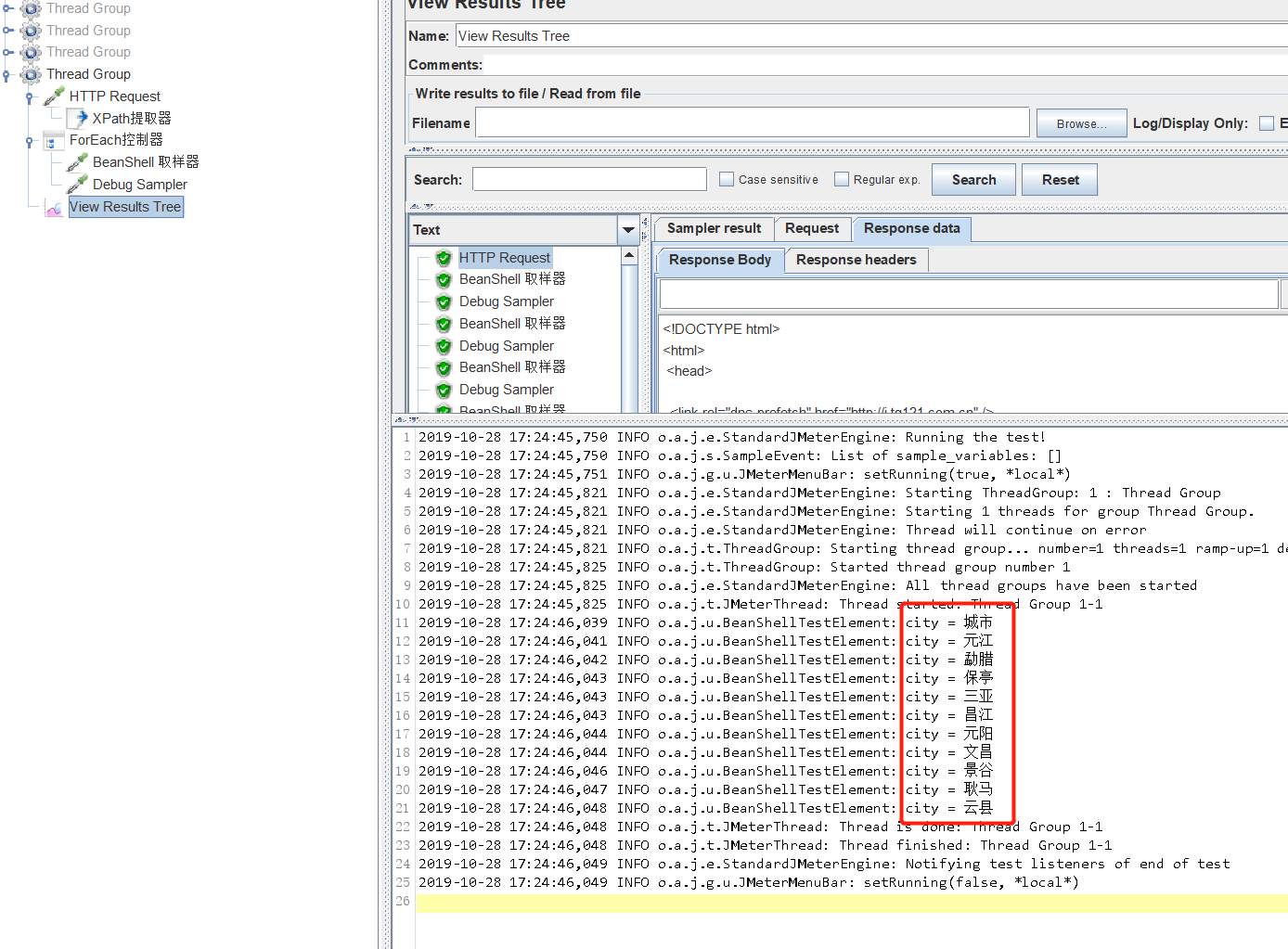
我们提取出来的东西都在list里,大小位置,因此使用foreach循环,从0开始,0不包含,刚好把匹配项第一个给过滤掉。
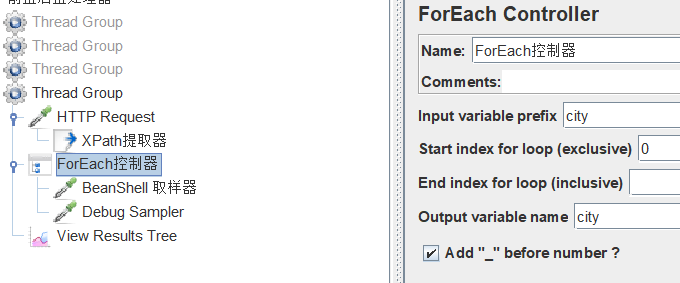
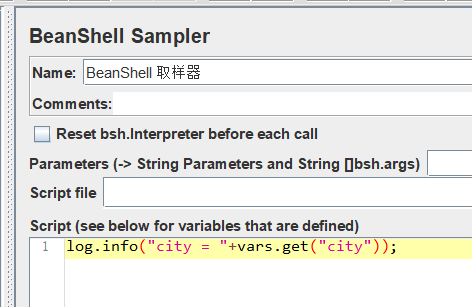
打印一下。
查看结果,都取到了。
8.XPath2 Extractor
XPath2提取器,还没仔细研究过,应该跟XPath提取器差不多,后面再补充。
9.BeanShell PostProcessor
BeanShell后置处理程序, 这个和前置的差不多,功能也是十分强大,如果上述处理器没法满足你,就可以通过beanshelll postprocessor自定义代码来实现功能。
语法格式等参考BeanShell取样器。